AI学習高速化の鍵、ハイパーパラメータ自動最適化
AI、特に大規模言語モデル(LLM)の分散学習では、テンソル並列やパイプライン並列、マイクロバッチサイズなど、多くのパラメータが学習効率に影響を与えます。これらの「ハイパーパラメータ」を最適に設定することで、AIの学習速度は大きく向上します。しかし、最適な組み合わせを見つけるには専門知識と膨大な試行錯誤が必要で、AI開発エンジニアにとって大きな負担となっていました。
AIBoosterは、この探索プロセスを自動化することで、エンジニアの作業効率向上を支援します。AI学習効率の向上は、限られたGPU資産を最大限に活用し、GPU導入費や電力消費量などのAI関連コストを低減させることにつながります。また、短時間でAI学習を多く試行できるようになるため、より精度の高いAIモデルの開発が可能となり、AI開発の時間と品質の両面で効率化が図れると見込まれます。
独自アルゴリズムによる劇的な性能改善
フィックスターズは今回、Megatron Coreの並列化戦略に関するドメイン知識を活かし、ハイパーパラメータ探索に「ヒューリスティック探索」と「Staged BlackBox探索」という2種類の独自アルゴリズムを新たに実装しました。
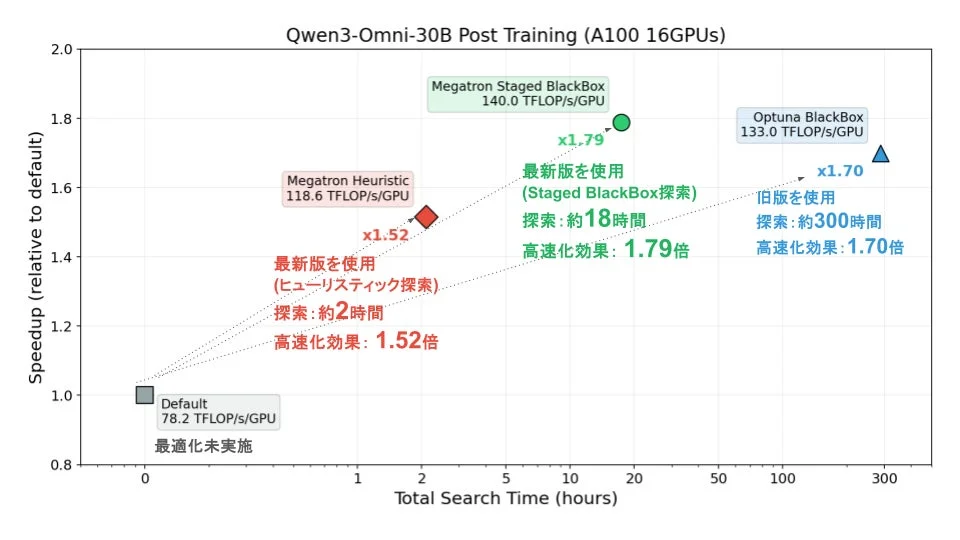
NVIDIA A100×16GPU環境でQwen3-Omni-30Bの事後学習(SFT)を対象としたベンチマークテストでは、以下の成果が確認されています。

-
ヒューリスティック探索: 約2時間の探索で学習スループットを78.2から118.6 TFLOP/s/GPUに向上させ、1エポックあたりの学習時間を約1.52倍高速化しました。これは、従来約300時間かけて約1.7倍の高速化効果を得ていたのに対し、その約1/150の時間でほぼ同等の効果を得られることを意味します。
-
Staged BlackBox探索: 約18時間の探索でスループットを140.0 TFLOP/s/GPUまで引き上げ、約1.79倍の学習時間高速化を実現しました。従来のBlackBox最適化アルゴリズム(Optunaベース)と比較して、約1/16の探索時間でより優れたハイパーパラメータを取得できることが示されています。
これらのアルゴリズムは、ユースケースに応じて使い分けが可能です。短時間で実用的な高速化性能を得たい場合はヒューリスティック探索を、さらに高い高速化を追求する場合はStaged BlackBox探索を利用すると良いでしょう。
ノーコードで手軽にチューニング
本バージョンでは、Pythonスクリプトの記述が不要となり、コマンドライン操作のみでチューニングを実行できる「ノーコード機能」も追加されました。これにより、専門知識がないエンジニアでも高精度なハイパーパラメータ最適化をすぐに活用できるようになり、AI開発の敷居がさらに下がると期待されます。
Fixstars AIBoosterとは
Fixstars AIBoosterは、AI学習・推論などのAIワークロードにおいて、計算資源の利用効率を最適化し、最高のパフォーマンスを引き出すための包括的なソリューションです。主に以下の3つの機能を提供します。
-
パフォーマンス・オブザーバビリティ(PO): GPUなどのハードウェア利用状況やソフトウェア実行プロファイルを継続的に記録・可視化し、性能変化やボトルネックを把握します。
-
パフォーマンス・インテリジェンス(PI): ボトルネックの分析、自動高速化、AIエージェントによる改善提案、エキスパートによるレビューなどを通じて、AIワークロードの継続的な性能向上を支援します。
-
最適化されたAIインフラ: POとPIで得られた知見に基づき、顧客のAIワークロードに最適なインフラ(パブリッククラウド、プライベートクラウド、オンプレミスなど)を合わせて提供します。
フィックスターズは、AIBoosterを中核として、AIサービスプロバイダーやAIを活用した組み込みアプリケーションを開発・提供する事業者に対し、トータルソリューションを提供していく方針です。
AIBoosterの詳細については、以下のリンクをご覧ください。
株式会社フィックスターズについて
フィックスターズは、「Speed up your AI」をコーポレートメッセージに掲げ、計算資源を最大限に活用するソフトウェア最適化技術を用いて、AIモデルの推論処理と学習プロセスの両面で高速化を実現するテクノロジーカンパニーです。医療、製造、金融、モビリティなど多岐にわたる分野で、次世代AI技術の進化を推進しています。


コメント